Index Metrics
Troubleshooting issues with your index starts with metrics. Read on to learn how to read, interpret, and act on your Solr metrics charts.
Navigating to Metrics
The Metrics dashboard is located in each index dashboard. Log into Websolr, click on your index, and click on the metrics tab.
Metrics utilities
Time Window Selector
 Use this selector to choose between 4 window sizes:
Use this selector to choose between 4 window sizes:
- The last 1 hour (1h)
- The last 24 hrs (1d)
- The last 7 days (7d)
- The last 28 days (28d)
Time Scrubber
Click on the arrows to go back or forth in time within the same time window size.
UTC and Local Timezone Toggle
Click on the timezone to toggle between displaying the graph timestamps in UTC time or your local timezone.
Highlighting
 You can drill down to smaller windows of time on any graph by clicking and dragging to select a time range.
You can drill down to smaller windows of time on any graph by clicking and dragging to select a time range.
Metrics Overview
More information doesn’t necessarily mean more clarity. When something unexpected happens to your Solr traffic, it’s important to know how to see your metrics and draw conclusions
Below we’ll cover what each graph displays and some examples of what they will look like given certain use cases, like high-traffic or indices in different states (normal, or experiencing downtime). We’ll start with the most information-dense graph: the request heatmap.
Performance Heatmap
This graph reveals how fast requests are. Each column in the graph represents a “slice” of time. Each row, or “bucket”, in the slice represents duration speed. The ‘hotter’ a bucket is colored, the more requests there are in that bucket. To further help visualize the difference in the quantity of requests for each bucket, every slice of time can be viewed as a histogram on hover.
Example 1
 This heatmap displays a healthy index with a lot of traffic, and some slow request times (toward the top), but a majority of it is occurring below 40ms.
This heatmap displays a healthy index with a lot of traffic, and some slow request times (toward the top), but a majority of it is occurring below 40ms.
Example 2
 Here we have an index with very little traffic. It’s important to note that the ‘heat’ color of every bucket is determined relative to the other data in the graph - so a side-by-side comparison of two request heatmaps using color won’t be accurate.
Here we have an index with very little traffic. It’s important to note that the ‘heat’ color of every bucket is determined relative to the other data in the graph - so a side-by-side comparison of two request heatmaps using color won’t be accurate.
Request Counts
This graph is straightforward: it shows the number of requests handled by the index at a given time.

Request Duration Percentiles
The request duration graph, similar to the request heatmap, shows a distribution of request speed based on three percentiles of the requests in that time slice: 50%, 95%, and 99%. This is helpful in determining where the bulk of your requests sit in terms of speed, and how slow the outliers are.

Queue Time
Queue time is the total amount of time requests were “queued” or paused at our load balancing layer. Ideally, the queue time is 0, but in the event that you send many requests in parallel, our load balancer will queue up requests while waiting for executing requests to finish. This is part of our Quality of Service layer.

Concurrency
Concurrency shows the number of requests that are happening at the same time. Since indices are limited on concurrency, this can be an important one to keep an eye on. When you reach your plan’s max concurrency, you will notice queue time start to consistently increase.

Bandwidth
This graph shows the amount of data crossing the network - going into the index (shown in green), and coming from the index (in blue).
We expect most bandwidth graphs to look something like the graph below — a relatively higher count of ‘from client’ data compared to ‘to client’ data. These bars show the relationship of read and write data; the ‘To Client’ data coming from write - or indexing - requests, and the ‘From Client’ data the result of read requests.
 The relationship between green to blue bars in this graph really depends on your use-case. A staging index, for example, might see a larger ratio of Write:Read data. It’s important to note that this graph deals exclusively in data - a high-traffic index will probably see a lot of data coming “From” the index, but a low-traffic index with very complicated queries and large request bodies will also have a larger “From Client” data than would otherwise be expected. Therefore, it’s helpful to look at request counts to get a feeling for the average ‘size’ of a request.
The relationship between green to blue bars in this graph really depends on your use-case. A staging index, for example, might see a larger ratio of Write:Read data. It’s important to note that this graph deals exclusively in data - a high-traffic index will probably see a lot of data coming “From” the index, but a low-traffic index with very complicated queries and large request bodies will also have a larger “From Client” data than would otherwise be expected. Therefore, it’s helpful to look at request counts to get a feeling for the average ‘size’ of a request.
Response Codes
This graph can do two things:
- It will confirm that responses are successful: 2xx responses. This means that everything is moving along well and requests are formed correctly.
- In the less positive case, it can be a debugging tool that can help figure out where any buggy behavior is coming from. In general, 4xx requests are the result of a malformed query from your app or some client, whilst a 5xx request is from our end.
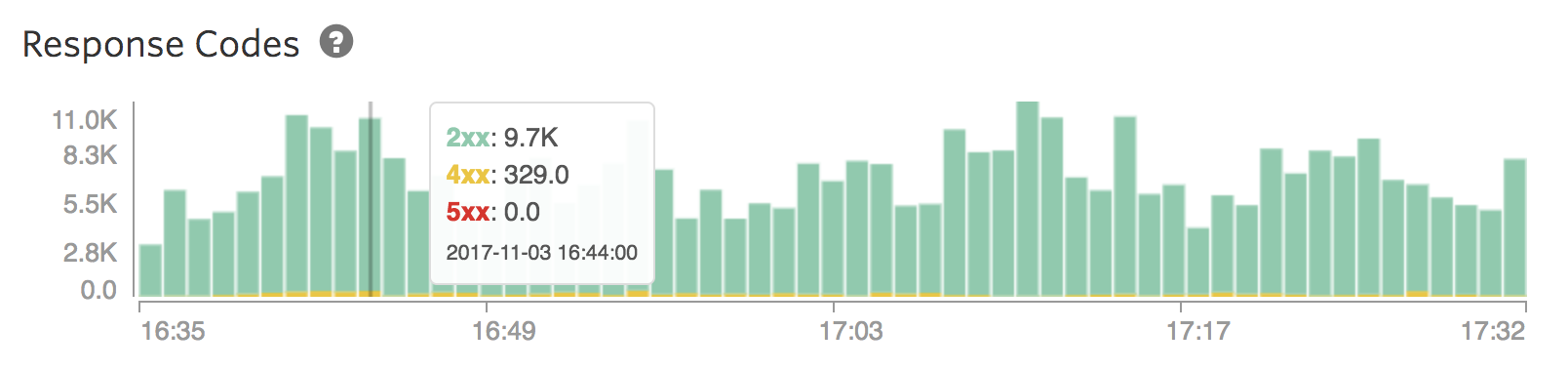 It’s important to note while reading this graph, that 5xx requests don’t necessarily mean that your index is down. A common situation on shared-tier architecture is an index that’s getting throttled by a noisy neighbor who’s taking up a lot of resources on the server. This can interrupt some (but not all) normal behavior on your index, resulting in a mix of 2xx and 5xx requests.
It’s important to note while reading this graph, that 5xx requests don’t necessarily mean that your index is down. A common situation on shared-tier architecture is an index that’s getting throttled by a noisy neighbor who’s taking up a lot of resources on the server. This can interrupt some (but not all) normal behavior on your index, resulting in a mix of 2xx and 5xx requests.
Tolerance for a few 5xx requests every now and then should be expected with any cloud service. We’re committed to getting all production indices a 99.99% uptime (i.e. expected 0.001% 5xx responses), and we often have a track record of 4 9’s and higher. See our uptime history here:
We have a lot of people that are very sensitive to 5xx requests. In these cases, it’s usually best to be on a higher plan or a dedicated setup. Reach out to us at support@websolr.com if this is something your team needs.